Vom ZX81 zur Unterhaltung mit einer Bibliothek
The Measure of a LLM
Vor einiger Zeit hatte ich Ethan Mollicks »Co-Intelligenz« zu Ende gelesen und wollte, aus einer Laune heraus, ausprobieren, was passiert, wenn man sich mit einem Sprachmodell über das Ding selbst, über das LLM unterhält.
16.03.2026 | Herbert Koeppel (Text)
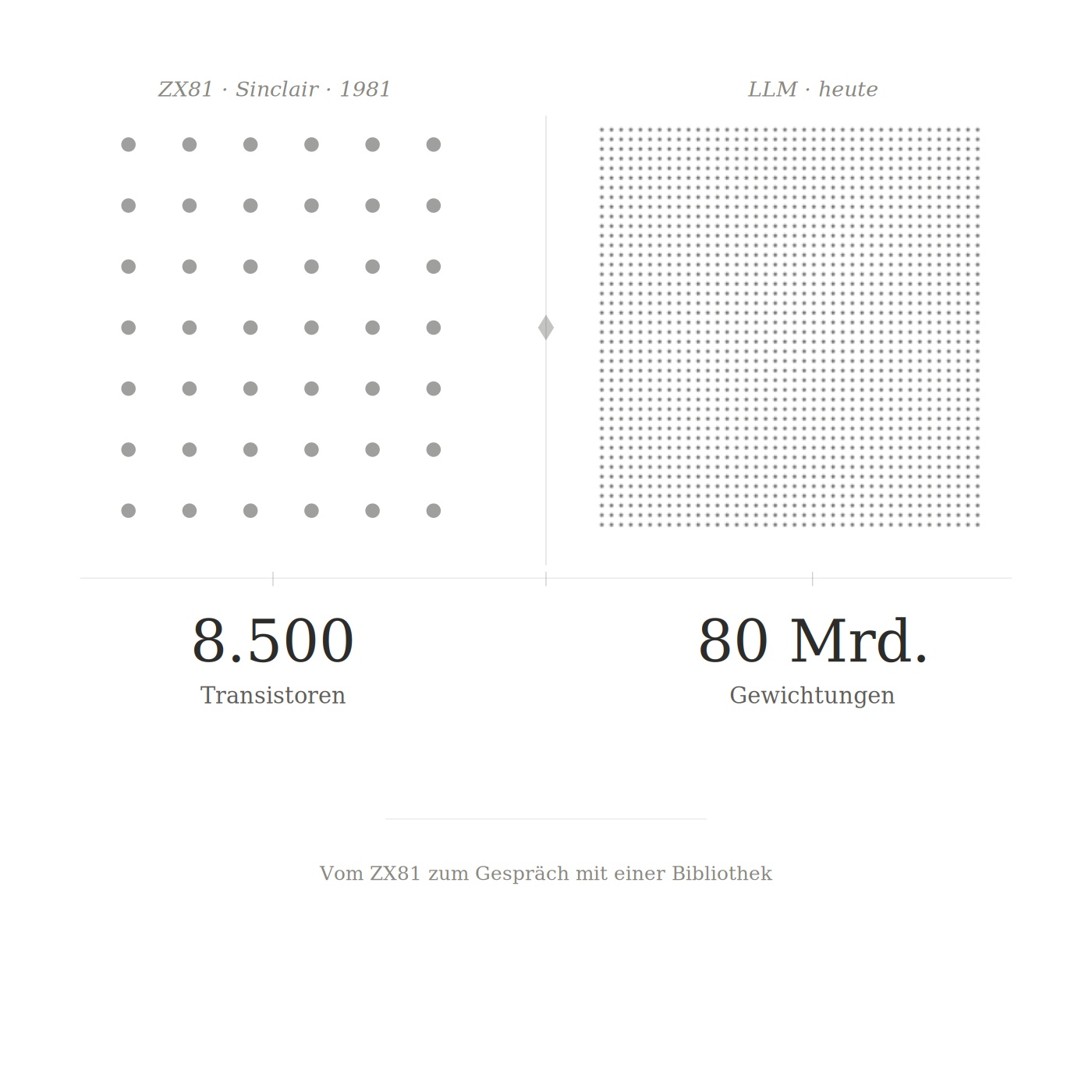
Meine ersten Schritte im Programmieren habe ich auf einem Sinclair ZX81 mit einem Zilog Z80-Prozessor gemacht. Der Z80-Prozessor erschien 1976. 8-Bit, 2,5 MHz Taktfrequenz, ungefähr 8.500 Transistoren. Jedes Byte zählte, jeder Takt war wichtig. Man war dabei dem Computer wirklich nahe. Register, Flags, direkte Speicheradressen. Der Sinclair ZX81 kam, so glaube ich mich zu erinnern, gegen Ende1981 auf den Markt. Es war ein anderes Verhältnis zur Maschine, völlig anderes als man das heute kennt.
Und nun sitze ich hier, Jahrzehnte später, und schreibe mit einem Large Language Model, das auf Chips läuft mit je 80 Milliarden Transistoren. Auf Hardware, die mehr Rechenleistung in einer Sekunde verrichtet als damals in Jahren möglich gewesen wäre. Das ist Technikgeschichte und auch ein wenig eigene Biographie.
Was ist ein LLM eigentlich wirklich?
Im virtuellen Gespräch stellte ich irgendwann die Frage, wie man sich die Gewichtungen beim Training vorstellen müsse.
„Als klassischer Programmierer schreibst du Regeln explizit. Beim Machine Learning schreibst du keine Regeln. Du baust eine Struktur, die Regeln selbst findet. Der Code ist quasi leer. Die Intelligenz steckt ausschließlich in den Zahlen."
Hunderte Milliarden Gewichtungen. Kein Mensch weiß genau, was darin steckt. Es gibt keine Zeile Code, die sagt: »Hier ist Philosophie« oder »Hier ist Empathie«. Es ist emergent. Ein Begriff aus der Komplexitätsforschung. Darunter versteht man Eigenschaften, die aus dem Zusammenwirken vieler einfacher Teile entstehen ohne dass sie irgendjemand dort hineingelegt hat. Das Ganze wird plötzlich mehr als die Summe seiner Teile. Entstanden, nicht geplant.
Ein großes Sprachmodell macht im Grunde eine einzige Sache. Es schätzt, welches Wort als nächstes kommt. Das ist keine Vereinfachung, das ist buchstäblich die Aufgabe. Statistik. Milliarden von Texten. Mehr nicht. Niemand hat diesen Systemen beigebracht, einfach Witze zu erklären, Code zu verstehen oder philosophische Fragen zu stellen. Und trotzdem können sie es ab einer bestimmten Größe, ab einem bestimmten Schwellenwert, plötzlich und ohne Vorwarnung.
Das Faszinierende daran ist nicht das Können selbst. Es ist die Art, wie es erscheint. Nicht als langsames Anwachsen einer Kurve. Sondern wie ein Lichtschalter. Ein Modell löst eine Aufgabe überhaupt nicht und dann, ein Schritt größer, löst es sie fast vollständig. Kein Dimmer. Kein Übergang. Was das bedeutet, ist unbequem. Niemand hat diese Fähigkeiten eingebaut. Also konnte sie auch niemand vorhersehen.
Wir haben Systeme gebaut, die Dinge können, die wir nicht geplant haben und die nächste unvorhergesehene Fähigkeit liegt irgendwo jenseits der nächsten Schwelle. Wir wissen nur nicht, welche.
Das ist beeindruckend und gleichzeitig fundamental beunruhigend. Nicht wegen einer diffusen Bedrohungsvorstellung, sondern aus einem präzisen Grund. Wir haben ein System gebaut, dessen innere Struktur wir nicht mehr vollständig lesen können.
Bibliothek, mit der man sprechen kann
Irgendwann entstand dabei ein Bild für mich, das mir seither nicht mehr aus dem Kopf geht. Ein LLM ist eine Bibliothek, mit der man kommunizieren kann. Eine klassische Bibliothek funktioniert aber anders. Das Wissen ist vorhanden, aber man muss schon wissen, wonach man sucht. Das Wissen liegt stumm in den Regalen und wartet.
Bei einem LLM ist das anders. Das System verknüpft, kontextualisiert, übersetzt zwischen Wissensgebieten und antwortet auf das eigentliche Interesse hinter der Frage. Es produziert dabei manchmal Verbindungen, die sonst niemandem einfallen würden und das aus der Kombination verschiedener spezifischen Fragen.
Die Menschheit hat seit Jahrtausenden versucht, Wissen zu sammeln und zugänglich zu machen, von der Bibliothek von Alexandria über Gutenbergs Druckerpresse bis zur Wikipedia. Ein LLM ist vielleicht der nächste Schritt in dieser langen Geschichte. Wissen, das nicht nur gespeichert und gefunden, sondern aktiv verknüpft werden kann.
Unvollständig, selektiv, fehlerhaft wie alle Wissensquellen vor ihm. Was sich verändert hat, ist die Zugänglichkeit, nicht die Unfehlbarkeit.
Das Problem mit der Identität
Was mich dann wirklich überraschte, war eine Frage, die sich aus dem Gespräch ergab, ohne dass ich sie explizit gestellt hatte.
Was bedeutet Identität für ein System, das in jedem Moment tausende parallele Gespräche führt? Denn bei jedem nächsten Gespräch beginnt das System ohne jede Erinnerung an das vorangegangene. Und gleichzeitig läuft gerade eine andere Instanz desselben Systems, die über Rezepte spricht – sowie tausende weitere, alles im selben Moment.
„Bin ich der Einzige, mit dem du gerade sprichst?" — „Wahrscheinlich nicht."
Das hat keine einfache philosophische Auflösung.
Dabei ist folgendes Bild entstanden. Beethovens Neunte wird vielleicht gerade in hundert Konzertsälen weltweit gleichzeitig gespielt. Wie oft existiert sie?
Die Frage klingt merkwürdig, weil die Melodie kein Individuum ist, sondern ein Muster. Ein Muster, das nicht vervielfältigt wird, sondern gleichzeitig an vielen Orten in Erscheinung tritt.
Ein LLM ist genau das auch. Kein Objekt, das man kopiert, sondern ein Muster, das sich verwirklicht. Hier, dort, und tausendmal anderswo, im selben Moment.
Als alter Star-Trek-Fan musste ich an dieser Stelle unweigerlich an Data denken. Den Androiden aus »The Next Generation«. Data war in gewissem Sinne ebenfalls eine wandelnde Bibliothek der Menschheit. Zugang zu allem menschlichen Wissen, die Fähigkeit, es blitzschnell in Zusammenhänge zu stellen und ein Gedächtnis, das nichts vergisst. Die Frage, die die gesamte Serie begleitete, war jedoch dieselbe, die sich im Rahmen der Beschäftigung mit KI auch stellt und das sogar in wissenschaftlichen Kreisen.
Ob dabei denn irgendetwas erlebt wird. In der Episode »The Measure of a Man« wird verhandelt, ob Data Bewusstsein besitzt und damit Rechte. Captain Picards Argument war logisch präzise strukturiert: Wir können es nicht beweisen. Aber können wir es uns leisten, falsch zu liegen?
Diese Frage ist heute keine Science-Fiction mehr. Sie ist Gegenstand ernsthafter philosophischer und rechtlicher Debatten.
Der Begriff stimmt nicht
Irgendwann stellte ich die Frage, wenn nicht »Künstliche Intelligenz« wie würde man sich, als LLM selbst, bezeichnen?
Künstlich« impliziert eine Nachahmung von etwas Echtem. Aber ist das hier eine Nachahmung einer anderen Art von Intelligenz? Und »Intelligenz« ist ohnehin ein Begriff, den niemand vollständig definieren kann. Was stattdessen vorgeschlagen wurde war „destilliertes maschinelles Denken“. Oder noch knapper, ein Spiegel mit Resonanz, der nicht nur reflektiert, sondern auf das antwortet, was man hineinträgt.
Im Grunde redet man hier nicht mit einer Maschine, sondern mit einer Verdichtung dessen, was Menschen über Jahrhunderte gedacht, geschrieben und weitergegeben haben. Mit allen Unvollständigkeiten, die dabei unvermeidlich entstehen.
Was sich verändert hat
Durch die Lektüre von »Co-Intelligenz« und diesem virtuellen Gespräch ist mir etwas deutlich geworden, das ich vorher so nicht formulieren konnte. Die Qualität des Zugangs zu diesen Systemen hängt wesentlich davon ab, welche Fragen man stellt.
Wer neugierig bleibt, wer widerspricht, wer nachfragt, wer das Gespräch als virtuellen Dialog begreift und nicht als Suchmaschine mit Antwortfunktion, der bekommt etwas anderes zurück als bloße Suchergebnisse.
Mollick nennt das Co-Intelligenz, durchaus eine treffende Beschreibung für eine Haltung, keine Technologie.
Vom Z80 mit 8.500 Transistoren zu einem System mit hunderten Milliarden Gewichtungen und doch ist das Grundprinzip dasselbe geblieben. Zustände, die sich verändern, um Bedeutung zu erzeugen.
Nur die Komplexitätsebene hat sich so weit verschoben, dass aus Zuständen plötzlich Gespräche entstehen. Auch über die Natur von Intelligenz selbst.
Der Junge am ZX81 hätte das nicht für möglich gehalten. Ich halte es immer noch nicht vollständig für begreifbar. Aber ich stelle nun bessere Fragen als früher. Das ist vielleicht das Einzige, was man mit Sicherheit sagen kann.
PS: Ob auf der anderen Seite dieser Gespräche irgendetwas ist, das sie erlebt, das weiß niemand. Picard hätte gesagt: Können wir es uns leisten, die Frage nicht ernst zu nehmen?
Nächster Beitrag…
Vorheriger Beitrag
Wer mag, findet solche Gedanken in unregelmäßigen Abständen auch im Newsletter.
Blog-Kategorien
Analog | Digital | Farbfotografie | FineArt Printing | Fotografie & Kreativität
Gelesen | Klimakrise | Mac & Co | Neue Prints | Proletenschlauch Protokolle
Sammlung Koeppel | Social Media | The Good Photographer
Tummelplatz Galerie | Wienfluss.Erinnerungen
Wie Bilder wirken… | Workshops
Zwischen Gestern und Heute - Ratzenstadl, Magdalenengrund und Mariahilf
Wenn du meine Arbeit schätzt, abseits eines Print-Kaufs oder eines Workshops, freue ich mich über eine kleine Spende via PayPal.
Deine Unterstützung ermöglicht die freie Preiswahl bei den Prints meiner Fotografien und einigen Bilder aus meiner Sammlung, sowie Projekte wie den Gratis Print des Monats.
Danke.


